ClickHouse in Action: Driving Electrum’s EV Data Platform

In today’s data-driven world, success isn’t just about having innovative products—it’s about harnessing the power of data to drive smarter decisions. At Electrum, our fleet of electric motorcycles is transforming urban transportation in Jakarta, but the real revolution happens behind the scenes. Every ride, every route, and every performance metric generates valuable data that fuels our operations.

In our previous post, we explored how understanding the market and focusing on user-centered solutions have been essential to advancing sustainable urban mobility. But as our fleet has grown to over 3,000 bikes, supported by more than 250 battery swap stations (BSS) and covering an average of 220 kilometers daily, the scale and complexity of our data needs have skyrocketed. Collecting data alone is no longer enough—we need real-time, actionable insights to optimize fleet performance, streamline operations, and respond quickly to any issues.
Hi, I’m Andi Pangeran, Principal Software Engineer at Electrum.id. In this post, I’ll take you through how we scaled Electrum’s data platform to meet these challenges, the technical hurdles we overcame, and how our approach has become a cornerstone of our growth strategy.
What Electrum Needed in a Data Platform
As our fleet expanded, we didn’t just need to store data—we needed to turn it into useful insights. Our two main requirements were real-time insights and scalability. Here’s what we needed:
Fast, Flexible Query Performance
Real-time insights are crucial to our operations. For example, if a battery swap station isn’t working as expected, we need answers fast. In one case, we discovered that a station was running hotter than usual, which slowed down the battery charging process. Using fast queries, we identified the problem, moved the station to a better location, and improved its performance, preventing delays in service.
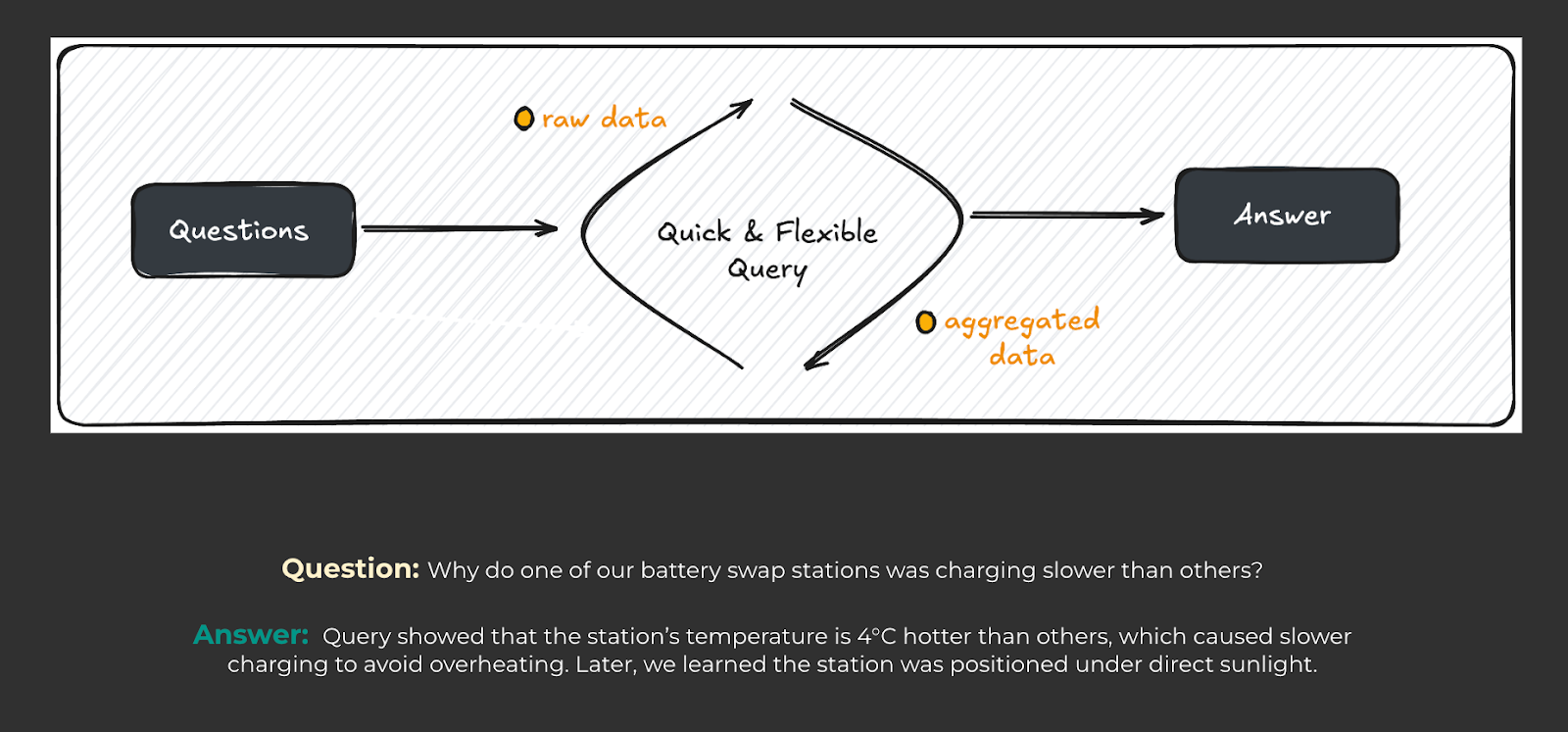
To maintain this level of responsiveness, we needed a platform that could handle different types of queries—whether it’s looking at data from a single bike or analyzing patterns across the whole fleet. We needed results in seconds, not minutes.
Scalable, Cost-Efficient Infrastructure

As more motorcycles hit the streets, the volume of data increased dramatically. Scaling our infrastructure wasn’t just about adding more storage; it had to be efficient and cost-effective. We needed a platform that could handle millions of records every day without slowing down or increasing costs. Scalability was essential to managing our data growth smoothly while keeping operational expenses under control.
Why ClickHouse Was the Perfect Fit
Given our needs for speed and scalability, we turned to ClickHouse, an open-source database created by Yandex that’s designed for fast queries on huge datasets.
ClickHouse is built for high-performance analytics, making it the ideal platform for our real-time operational requirements.
Here’s why ClickHouse works so well for us:
Columnar Storage
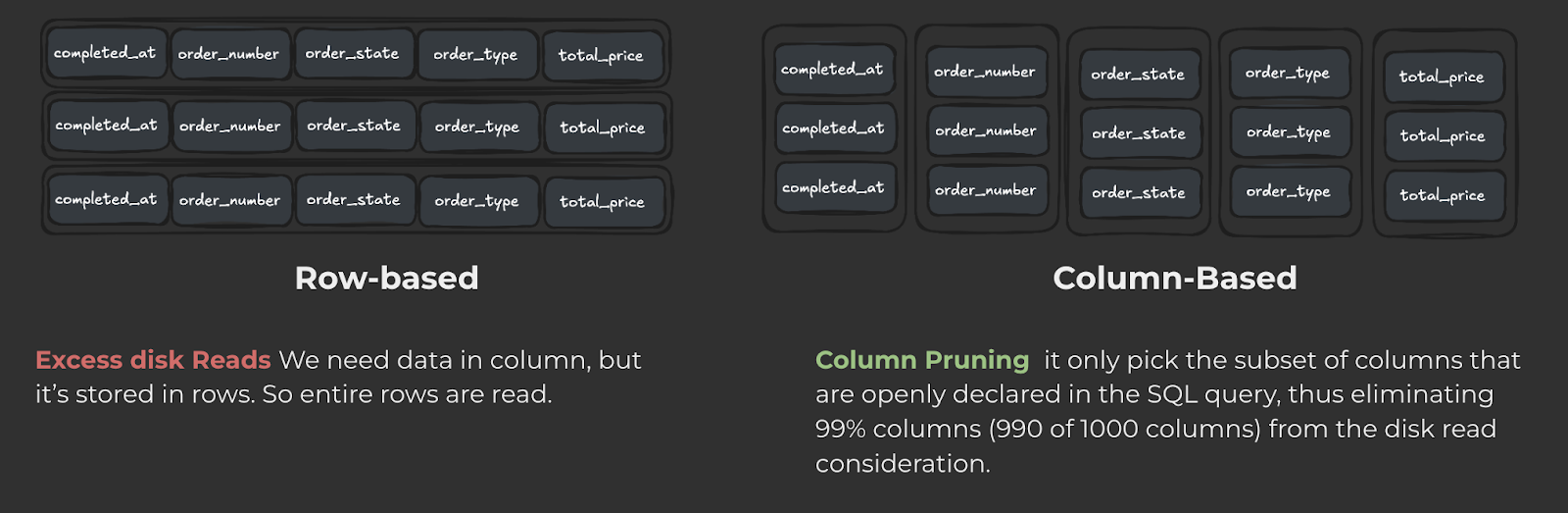
ClickHouse uses a column-based method for storing and retrieving data. Unlike traditional databases that read entire rows of data, even if you only need specific information, ClickHouse reads only the columns that are relevant to your query. This makes data processing faster and reduces the workload on the system.
For our large datasets, like battery health data from IoT sensors, this storage method allows us to quickly identify and solve operational issues.
Vectorized Execution
In addition to efficient storage, ClickHouse speeds up query processing with a technique called vectorized execution. Instead of handling data row by row, it processes large chunks of data at once. This approach, combined with a method called SIMD (Single Instruction, Multiple Data), allows multiple tasks to be done at the same time.
For example, when we need to filter or sort data from large datasets, ClickHouse can do it faster, saving us time and computing power.
Granule-Based Storage with Sparse Indexing and Skip Indexes
ClickHouse makes queries even more efficient with granule-based storage. Granules are small blocks of data, and ClickHouse accesses only the granules relevant to your query, reducing unnecessary reads and speeding up the process.
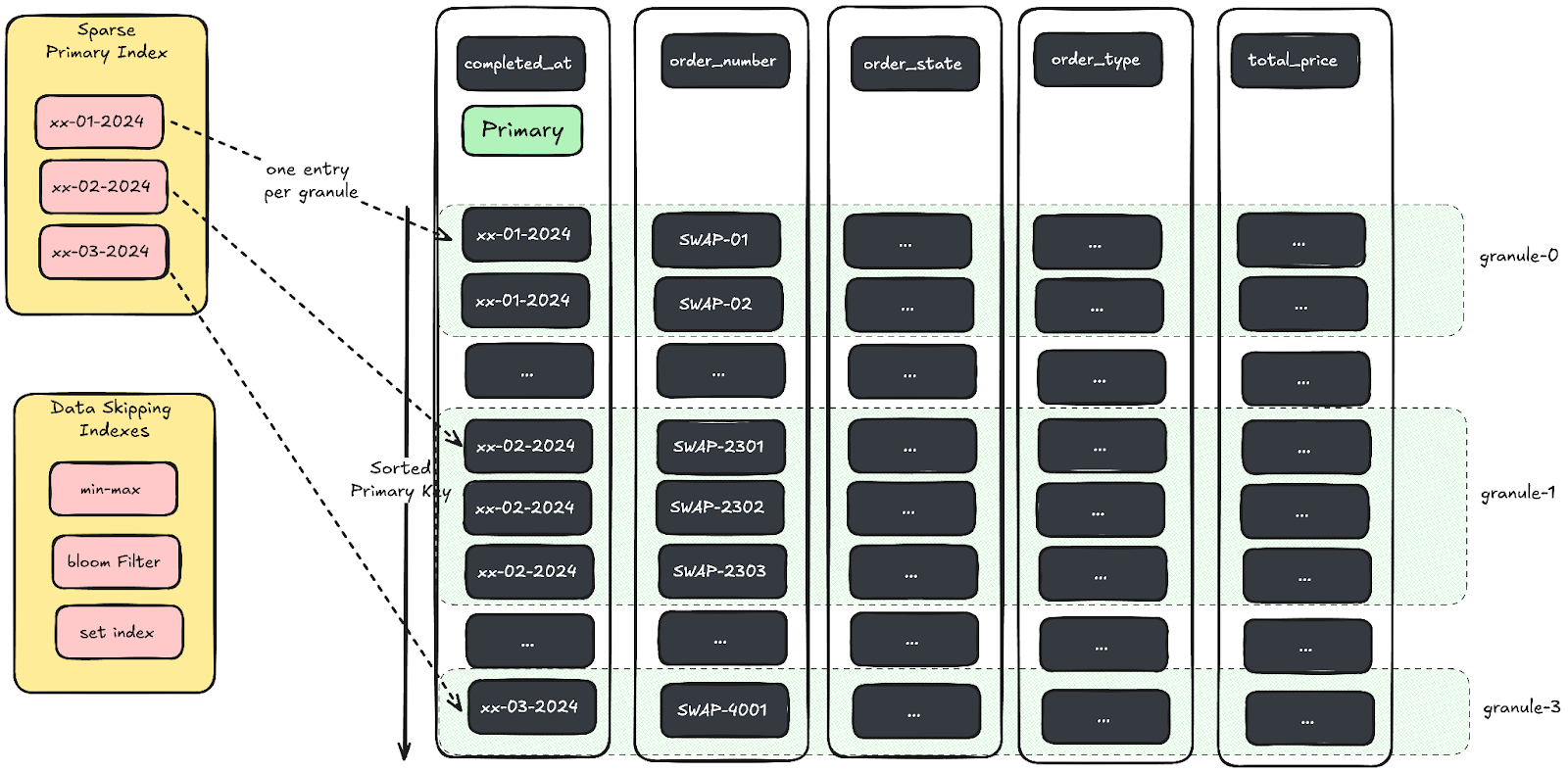
Paired with sparse indexing and skip indexes, ClickHouse can quickly locate the data it needs and skip over irrelevant sections. This is especially useful when we’re analyzing large datasets like daily travel logs from our entire fleet.
MergeTree Family and Merge Operations
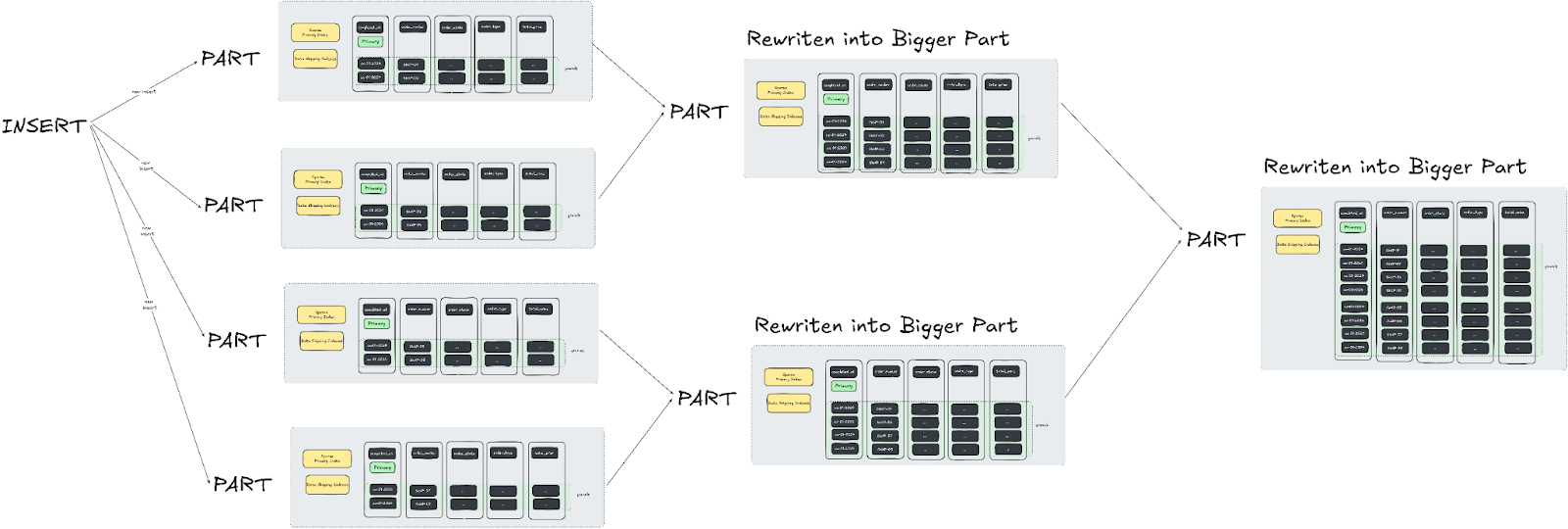
ClickHouse uses a set of engines called the MergeTree family to manage how data is stored, updated, and queried:
- MergeTree: Organizes data into parts, which are merged in the background. This keeps queries fast and allows for quick data insertions, making it ideal for handling large amounts of data that grow constantly, like logs.
- ReplacingMergeTree: For datasets that change frequently, like our IoT telemetry data, this engine automatically replaces older data with the latest version, ensuring we always work with up-to-date information.
- AggregatingMergeTree: This engine is used for generating summaries or reports. It combines rows with matching keys, making it easier to calculate things like totals or averages from large datasets.
These engines and their merge operations keep our data platform scalable, cost-efficient, and high-performing.
Diving Into Electrum’s Implementation with ClickHouse
Once we recognized that ClickHouse was the right choice for our data needs, we implemented it across our platform. ClickHouse’s scalability and performance allowed us to handle two core types of data: transactional data from customer interactions and IoT telemetry from our electric motorcycles.
We built a system that provides real-time insights and efficient data processing, giving both our business and operational teams the tools they need to make informed decisions at scale.
High Level Data Flow
Here’s how data flows through our system, with ClickHouse at the core:
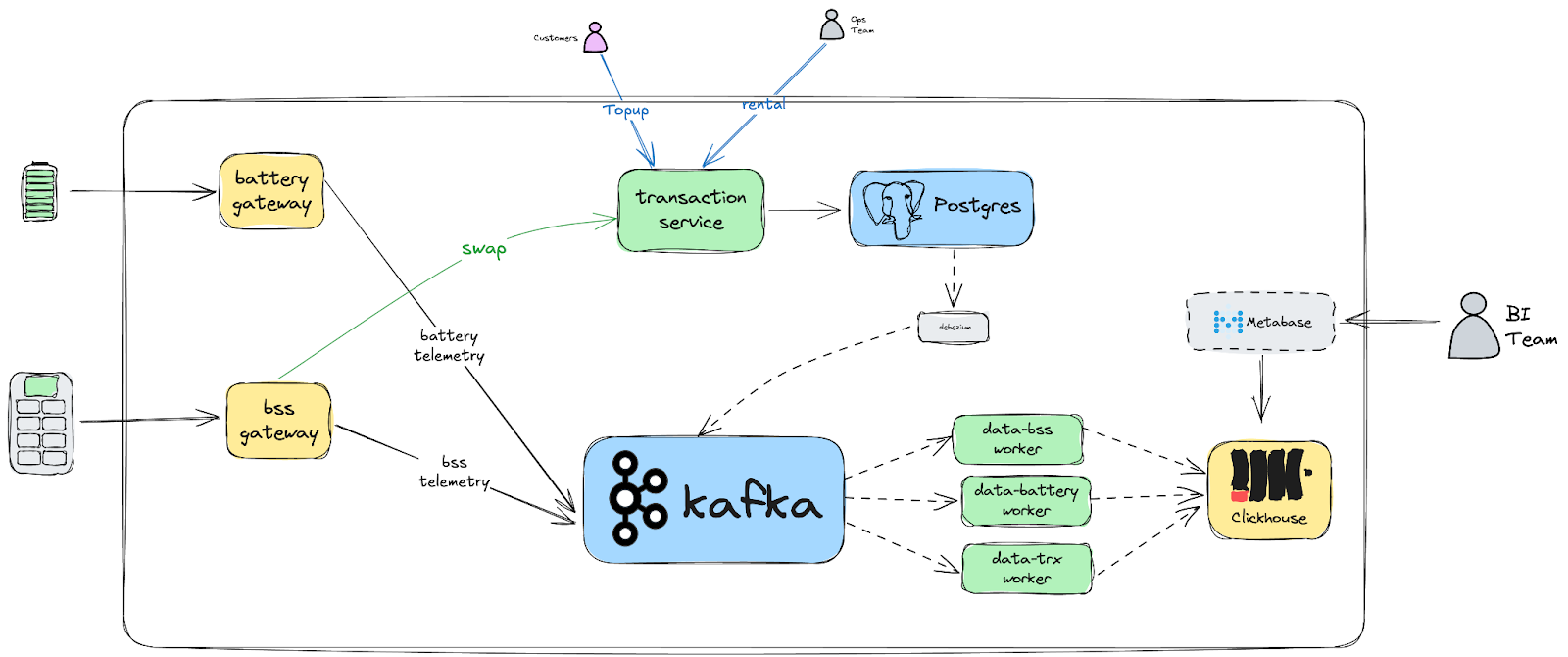
- Battery Gateway: Captures telemetry data from our motorcycles, like battery health, location, and performance.
- BSS Gateway: Collects data from battery swap stations (BSS).
- Transaction Service: Manages transactions like customer top-ups, rentals, and battery swaps.
- Kafka: Acts as the message broker, streaming real-time data into ClickHouse.
- ClickHouse: Stores and processes all the data from the gateways and transaction services.
- BI Analytics: Our BI team uses Metabase to run real-time analytics by querying ClickHouse. This gives us insights into fleet performance, customer behavior, and operational metrics.
Once the data is ingested via Kafka, it flows through dedicated workers that process the incoming information and write it into appropriate ClickHouse tables.
Key Use Cases: How ClickHouse Handles Our Data
1. Use Case: Transactional Data (Orders, Top-ups, and Rentals)
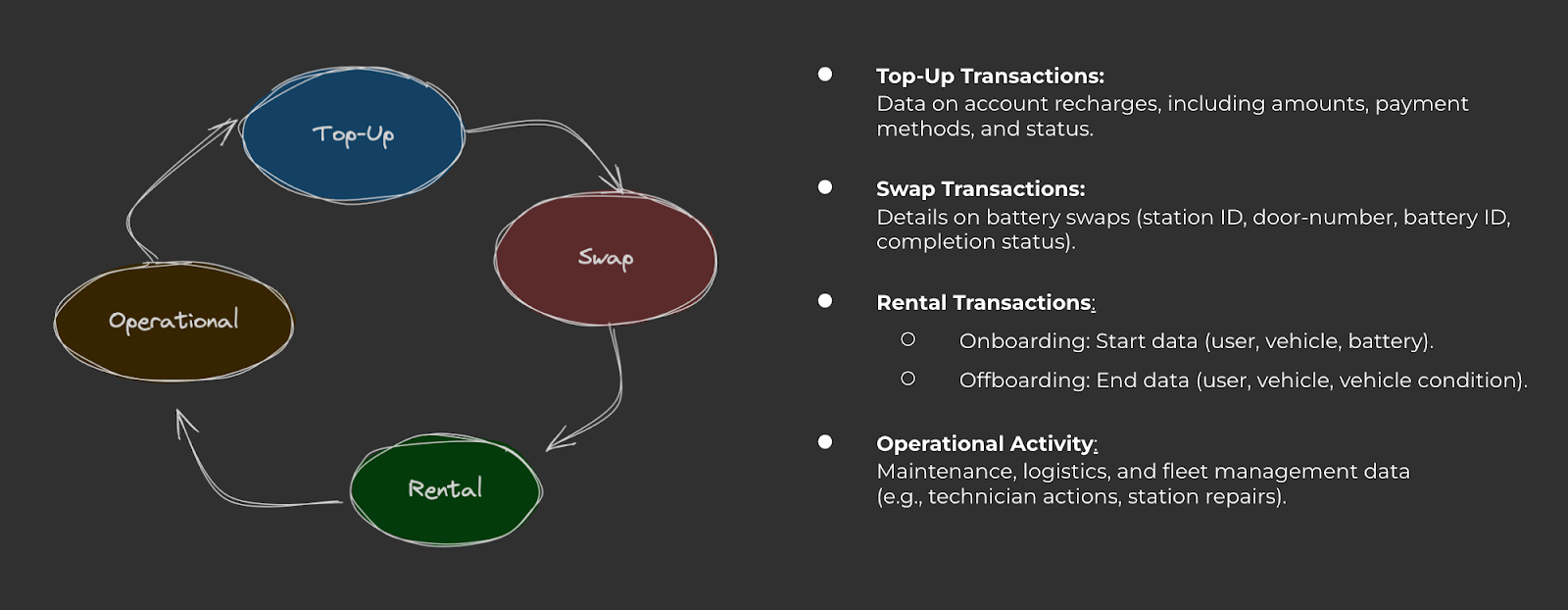
At Electrum, we process thousands of transactions each day, including battery swaps, rentals, and customer top-ups. Having a system that can track these transactions in real time is critical for both our operations and financial reporting.
CREATE TABLE IF NOT EXISTS trx_orders
(
id UInt64,
created_at DateTime64(3, 'UTC'),
completed_at DateTime64(3, 'UTC'),
customer_id UInt64,
customer_name LowCardinality(String),
order_number String,
order_state LowCardinality(String),
order_type LowCardinality(String),
total_price Int64,
INDEX idx_order_number order_number TYPE bloom_filter(0.01) GRANULARITY 1
)
ENGINE = ReplacingMergeTree(completed_at)
PARTITION BY toYYYYMM(completed_at)
ORDER BY (customer_id, completed_at, order_number, order_type)
SETTINGS index_granularity = 8192;sample schema of transaction tables
We chose ClickHouse’s ReplacingMergeTree engine to handle our transactional data because it’s specifically designed for datasets that are updated frequently.
For example, when an order changes states (like moving from “pending” to “completed”), ReplacingMergeTree automatically keeps only the most recent version of the data. This ensures we don’t store unnecessary duplicates, and any query always returns the latest, most accurate information.
Additionally, for business intelligence and monthly reports, we use materialized views to aggregate transaction data—such as the total number of orders and revenue per customer.
CREATE TABLE IF NOT EXISTS trx_agg_monthly_orders
(
year_month String,
customer_id UInt64,
order_type LowCardinality(String),
total_orders AggregateFunction(count),
total_revenue AggregateFunction(sum, Int64)
)
ENGINE = AggregatingMergeTree()
PARTITION BY year_month
ORDER BY (customer_id, year_month, order_type);
CREATE MATERIALIZED VIEW trx_agg_monthly_orders_mv
TO trx_agg_monthly_orders
AS
SELECT formatDateTime(completed_at, '%Y-%m') AS year_month,
customer_id,
order_type,
countState() AS total_orders,
sumState(total_price) AS total_revenue
FROM trx_orders
WHERE order_state = 'completed' -- Aggregating only completed orders
GROUP BY customer_id, order_type, year_month;MATERIALIZED View in realtime will act and store the record to target table
These materialized views are updated in real time as new data comes in, meaning our reports are always up to date without needing to rerun expensive queries.
2. Use Case: IoT Telemetry
Monitoring data from our electric motorcycles is another key part of Electrum’s operations. The IoT sensors on each bike provide critical information like battery voltage, charge cycles, and location, which helps us ensure the smooth operation and health of our fleet.
CREATE TABLE IF NOT EXISTS iot_battery_metrics
(
-- Timestamp of the recorded metric in high precision
`event_time` DateTime64(9) CODEC (Delta(8), ZSTD(1)) ,
-- Unique battery serial number (LowCardinality for optimized storage)
`battery_serial` LowCardinality(String) ,
-- Location data
`latitude` Float64 CODEC (ZSTD(1)),
`longitude` Float64 CODEC (ZSTD(1)),
-- Battery health indicators
`state_of_charge` Float64 CODEC (ZSTD(1)) ,
`state_of_health` Float64 CODEC (ZSTD(1)) ,
`charge_cycles` UInt32 CODEC (ZSTD(1)) ,
-- Battery electrical data
`battery_voltage` Float64 CODEC (ZSTD(1)) ,
`battery_current` Float64 CODEC (ZSTD(1)) ,
`battery_power` Float64 MATERIALIZED abs((battery_voltage / 1000) * (battery_current / 1000)) ,
-- Battery cell voltage
`cell_voltages` Array(Float64) CODEC (ZSTD(1)) ,
`min_cell_voltage` Float64 MATERIALIZED arrayMin(cell_voltages) ,
`max_cell_voltage` Float64 MATERIALIZED arrayMax(cell_voltages) ,
`voltage_difference` Float64 MATERIALIZED (max_cell_voltage - min_cell_voltage) ,
-- Battery temperature
`bms_temperature` Float64 CODEC (ZSTD(1)) ,
`cell_temperatures` Array(Float64) CODEC (ZSTD(1)) ,
`min_cell_temperature` Float64 MATERIALIZED arrayMin(cell_temperatures) ,
`max_cell_temperature` Float64 MATERIALIZED arrayMax(cell_temperatures),
INDEX idxevent_time event_time TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(event_time) -- Partition by date for optimized time-series queries
ORDER BY (battery_serial, toUnixTimestamp64Nano(event_time)) -- Ordered by battery and timestamp for efficient querying
TTL toDateTime(event_time) + toIntervalDay(30) -- Retain data for 30 days
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1;- For this high-frequency, time-series data, we use ClickHouse’s MergeTree engine.
- Additionally, we’ve implemented TTL (Time to Live) settings that automatically delete data older than threshold, allowing us to manage storage without sacrificing performance.
We also use a materialized view, example to track the last known location of each battery in real time.
CREATE TABLE IF NOT EXISTS iot_battery_last_location
(
battery_serial LowCardinality(String),
last_valid_latitude Float64,
last_valid_longitude Float64,
last_event_time DateTime64(9)
)
ENGINE = ReplacingMergeTree(last_event_time)
ORDER BY battery_serial
SETTINGS index_granularity = 8192;
CREATE MATERIALIZED VIEW IF NOT EXISTS iot_battery_last_location_mv
TO iot_battery_last_location
AS
SELECT
battery_serial,
latitude AS last_valid_latitude,
longitude AS last_valid_longitude,
event_time AS last_event_time
FROM iot_battery_metrics
WHERE latitude IS NOT NULL
AND longitude IS NOT NULL
AND latitude <> 0
AND longitude <> 0; Where Are We?
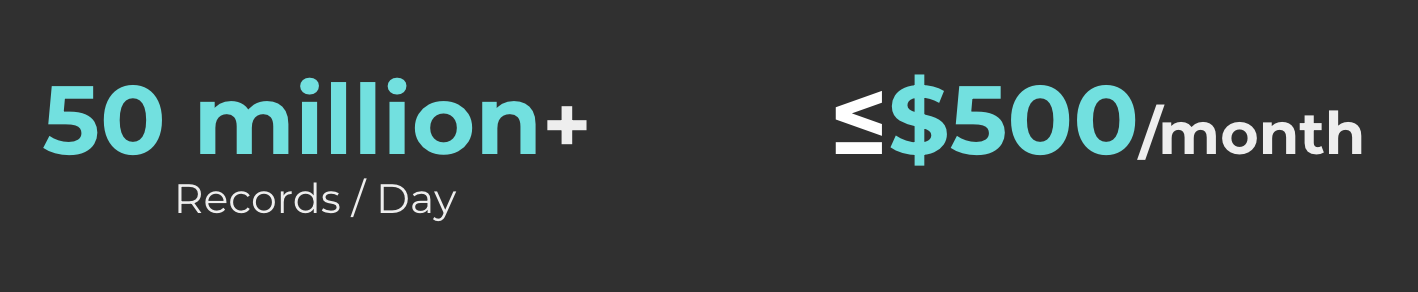
“ClickHouse enables us to have a data analytics capability that grows with our needs, while keeping costs low and predictable.” – Electrum.id
Today, ClickHouse sits at the heart of this system, empowering us with real-time analytics that scale seamlessly with our business. Processes over 50 million records per day, all while maintaining costs at less than $500 per month.
Lessons Learned and Technical Takeaways from Implementing ClickHouse
Implementing ClickHouse across our data platform wasn’t without challenges, but we learned some valuable lessons that helped us optimize our system.
Here are a few key takeaways:
- Optimizing Primary Key and Order-By Clauses: Selecting the right keys ensures efficient data sorting, which speeds up queries. Design them based on how data will be queried most often (e.g., by date or entity).
- Using Partitioning and Skip Indexes: Partitioning divides data for faster queries on time ranges or metrics, while skip indexes (like bloom filters) help avoid scanning irrelevant data.
- Managing Storage with TTL Policies: Time to Live (TTL) policies automatically delete outdated data, reducing storage costs while maintaining performance—especially for time-series data.
- Leveraging MergeTree Engines: Using the right MergeTree engine is crucial:
- ReplacingMergeTree manages frequent updates.
- AggregatingMergeTree pre-aggregates data, optimizing reporting.
- Reducing Load with Materialized Views: Materialized views precompute and store results of frequent queries, reducing system load, especially for real-time monitoring.
- Handling High Ingestion with Asynchronous Inserts: Asynchronous inserts decouple data ingestion from writes, preventing bottlenecks, especially during peak data traffic.
Have any of these lessons resonated with your own experiences in optimizing large-scale data platforms? We’d love to hear your thoughts and suggestions!
Learn More and Explore Our ClickHouse Demo
We shared our ClickHouse journey at the Jakarta Meetup on October 4, 2024. For a deeper technical dive, you can:
- View the full presentation slides here.
- Explore the key insights and technical challenges we addressed during the talk.
If you’re interested in experimenting with ClickHouse or setting it up in a production environment, check out my GitHub demo repository, which includes:
- Setting up a real-time ETL pipeline powered by Benthos
- Syncing and scaling data between databases with PostgreSQL and ClickHouse
- Automating infrastructure and deployment using GitOps (FluxCD) and real-time data streaming via Debezium and Kafka
Feel free to explore and apply these tools to your own projects!
Conclusion
At Electrum, integrating ClickHouse has enabled us to handle the growing amount of data generated by our fleet of electric motorcycles while maintaining real-time insights and operational efficiency at scale. ClickHouse’s robust architecture has made our data platform scalable and cost-efficient, supporting our long-term growth strategy.
If you’re interested in learning more about Electrum or exploring clean, sustainable transportation options in Jakarta, check out our latest promotions and offerings on our website.
What’s your take on the future of sustainable urban transportation? Join the conversation by sharing your ideas!
Thank you for following our journey!
Reference
- Why ClickHouse Is So FastChistaDATA Inc. (2023). Why ClickHouse Is So Fast.https://chistadata.com/why-clickhouse-is-so-fast
- How to Use ClickHouse Indexes: A Practical GuideChistaDATA Inc. (2023). How to Use ClickHouse Indexes: A Practical Guide.https://chistadata.com/how-to-use-clickhouse-indexes-practical-guide
- ClickHouse Skipping IndexesClickHouse Documentation. (2023). Skipping Indexes.https://clickhouse.com/docs/en/optimize/skipping-indexes
- ClickHouse OverviewYouTube. (2023). ClickHouse Overview.https://www.youtube.com/watch?v=QDAJTKZT8y4
- ClickHouse Architecture Deep DiveYouTube. (2023). ClickHouse Architecture Deep Dive.https://www.youtube.com/watch?v=iLXXoDaFoxs
- Optimizing ClickHouse PerformanceYouTube. (2023). Optimizing ClickHouse Performance.https://www.youtube.com/watch?v=BHcIEszF6Fk
- Supercharge Your ClickHouse Data Loads - Part 1ClickHouse Blog. (2023). Supercharge Your ClickHouse Data Loads - Part 1.https://clickhouse.com/blog/supercharge-your-clickhouse-data-loads-part1