Building a Cloud-Native Infrastructure for Indonesia's Electric Motorcycle Ecosystem: The Electrum Story

Introduction
Joining Electrum as a principal software engineer felt like stepping into an opportunity that perfectly balanced technical innovation and sustainability. The company’s mission—transforming how people navigate Jakarta through electric motorcycles and battery-swap technology—was ambitious but grounded in a clear vision. As someone passionate about building systems that make a tangible difference, I was drawn to the challenge of creating infrastructure to support this bold idea.
From the outset, we faced a clean slate. There was no existing cloud infrastructure, no predefined playbook, just a team with big ambitions and a lot of questions to answer. How could we design a platform that scales to support millions of trips while staying efficient, reliable, and innovative? How would we adapt as the industry, and our own needs, evolved?
Hello, it’s me again, Andi Pangeran, and I’m a Principal Software Engineer at Electrum. In this post, I’ll share the journey of building Electrum’s cloud-native infrastructure, from grappling with trade-offs to tackling unexpected challenges. Along the way, I’ll highlight what worked, what didn’t, and what we learned as we created a system designed to scale alongside Jakarta’s growing demand for cleaner urban transportation.
Let’s explore how we built a foundation for innovation.
The First Big Decision: Cloud Strategy
When we set out to build Electrum’s technology platform, the first big question was one every engineer dreads: Where do we even start? With no infrastructure in place, we had to decide how to build a system capable of powering a fleet of electric motorcycles, managing millions of trips, and analyzing countless data points—all while staying scalable, efficient, and adaptable.
This wasn’t just a technical decision. It was the foundation for everything we hoped to achieve. Get it wrong, and we’d face endless bottlenecks, spiraling costs, or systems that couldn’t grow with us. Get it right, and we’d have the flexibility to innovate and scale with confidence. The stakes couldn’t have been higher.
Weighing the Options
The first priority was obvious: cost. As a startup, every dollar mattered. We needed a solution that delivered value without cutting corners or locking us into trade-offs that might hinder growth. But saving money in the short term couldn’t come at the expense of long-term flexibility.
Equally important were scalability and speed to market. Our goal was to get technology into the hands of riders quickly and reliably. Jakarta’s streets wait for no one, and our reputation would rest on the smooth operation of battery swaps and fleet management from day one.
And then there was sustainability. Everything we do at Electrum revolves around minimizing environmental impact. Could our infrastructure align with that goal? Would it help us analyze data to optimize operations and reduce waste in real-time?
Choosing the Right Cloud Provider
We started with the usual suspects: AWS, Google Cloud Platform (GCP), and Microsoft Azure. Each offered similar capabilities on paper, but as we dug deeper, it became clear that our choice would hinge on alignment with two critical factors: the team’s expertise and the results of our initial proof-of-concept.
For our team, familiarity was key. AWS had the advantage here—it was a platform we knew well, with a robust ecosystem and tools that matched our needs. More importantly, our proof-of-concept with AWS had demonstrated the scalability and reliability we’d need as we expanded.

In the end, AWS wasn’t just a choice—it was the starting point for building something that could grow alongside our ambitions. With its comprehensive services and proven track record, it gave us the confidence to move fast while staying adaptable to future challenges.
DevOps as the Execution Framework
When building our cloud infrastructure from scratch, it quickly became clear that success wouldn’t just depend on technology choices but also on how we managed and delivered that technology. This is where DevOps became critical.
At its core, DevOps is a methodology that aligns development (Dev) and operations (Ops) to achieve faster, more reliable software delivery. It’s not about specific tools but about fostering collaboration and automating processes to build systems that are consistent, scalable, and adaptable. DevOps focuses on creating a seamless pipeline where code moves efficiently from a developer's keyboard to a running system, with minimal friction and maximum reliability.
The foundation of DevOps is automation. By automating repetitive tasks—provisioning servers, deploying code, running tests—we minimize human error, increase speed, and ensure that every process is repeatable and reliable. For Electrum, this wasn’t just a best practice; it was essential for achieving our goals of scaling infrastructure while maintaining the agility to support rapid growth.
Building DevOps from Scratch: Key Practices and Tools
Starting with a blank slate, we designed a DevOps framework to meet our needs for consistency, scalability, and speed. Here’s how we approached it step by step:
1. Infrastructure as Code (IaC): Laying the Foundation
The first step in implementing DevOps was to eliminate manual infrastructure management. We adopted Infrastructure as Code (IaC), using tools like Terraform and Terragrunt to define and manage our cloud infrastructure.
When we started with AWS, we spent considerable time deciding which Terraform modules to use. We compared community modules, Cloudposse, and Gruntwork to find the best match for our greenfield project. This evaluation wasn’t just about picking the most popular tools—it was about ensuring the modules aligned with our needs for scalability and maintainability.
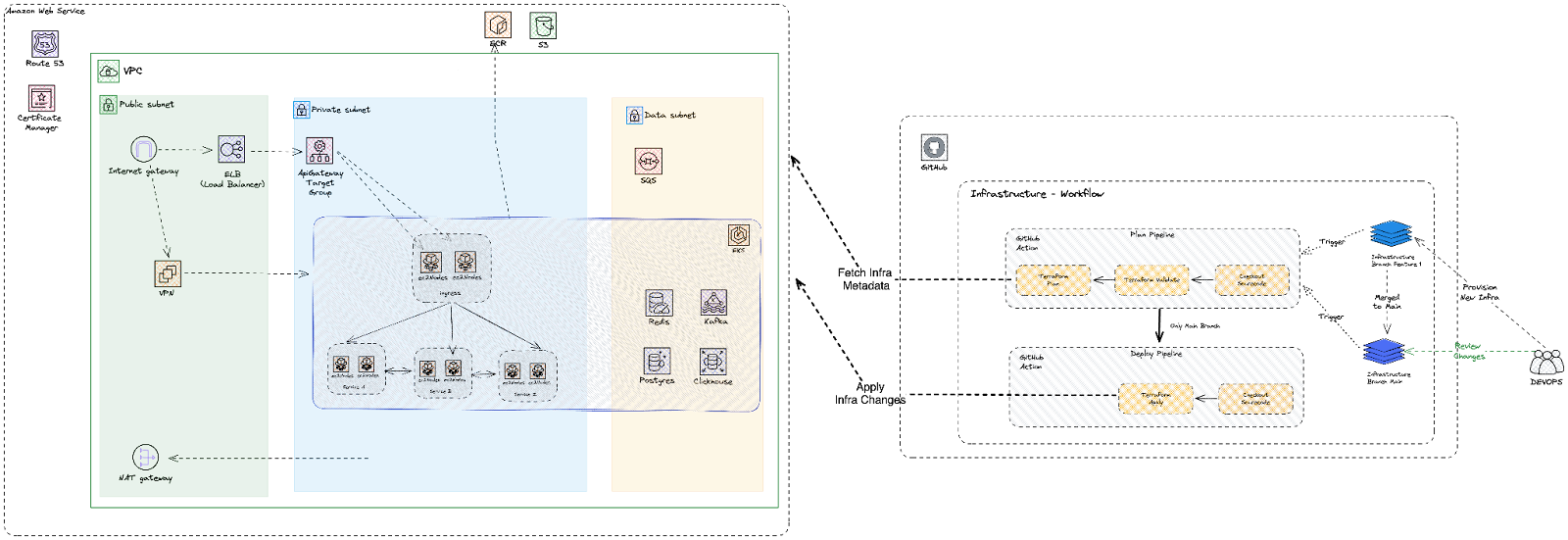
With IaC:
- Consistency was guaranteed: Every environment—development, staging, production—was provisioned identically.
- Traceability was built in: Infrastructure changes were stored in Git, making every adjustment version-controlled and auditable.
- Scalability became seamless: Spinning up new environments or scaling existing ones was as simple as running a script.
This automation meant we no longer relied on manual configuration, which saved time and reduced errors.
2. CI/CD: Automating the Development Lifecycle
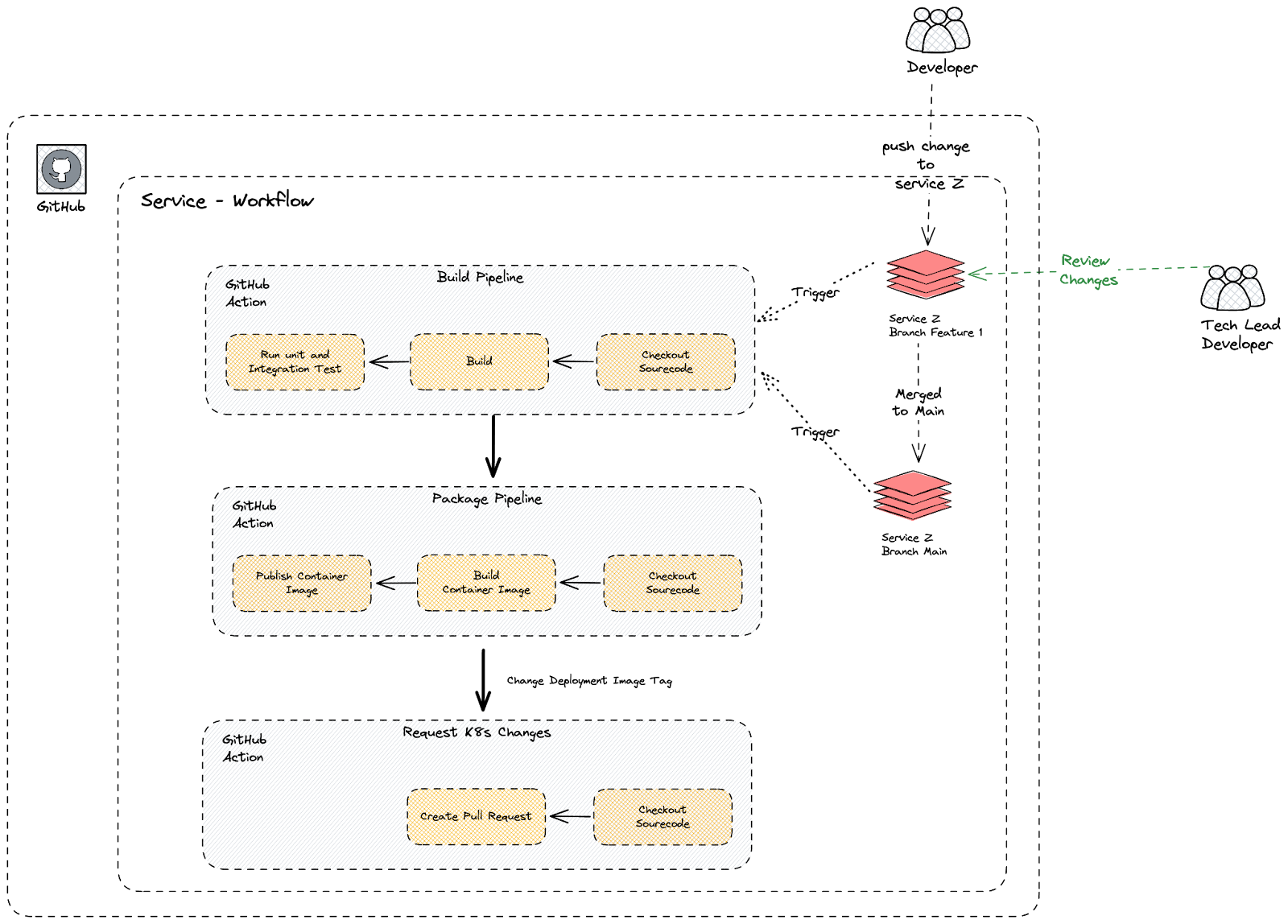
Once infrastructure was automated, we turned our focus to streamlining the software development lifecycle. Implementing Continuous Integration and Continuous Delivery (CI/CD) pipelines using GitHub Actions allowed us to automate the core stages of development:
- Testing: Application changes triggered unit tests, ensuring issues were caught early in the process.
- Building: Applications were containerized consistently, ensuring compatibility across environments.
- Deployments: Changes were deployed first to development and staging environments, where QA teams validated them. Only after passing QA did the pipeline proceed to deploy to the production environment.
In the early days, our deployment process was entirely manual, requiring engineers to coordinate releases. The breakthrough came when we introduced feature toggles for application changes. This allowed us to deploy features to production as part of regular releases without immediately exposing them to users. Instead, we could toggle features on or off as needed, ensuring safe, controlled rollouts.
With this approach, releases became routine, and deployments transformed into deploy-and-rollout processes. This shift not only improved deployment frequency but also gave the team confidence to ship changes rapidly while minimizing risks to production systems.
3. GitOps: Managing Kubernetes with Confidence
Managing Kubernetes clusters was a critical part of our DevOps implementation. As our infrastructure grew in complexity, maintaining control and ensuring consistency became paramount. By adopting GitOps principles with FluxCD, we ensured that:
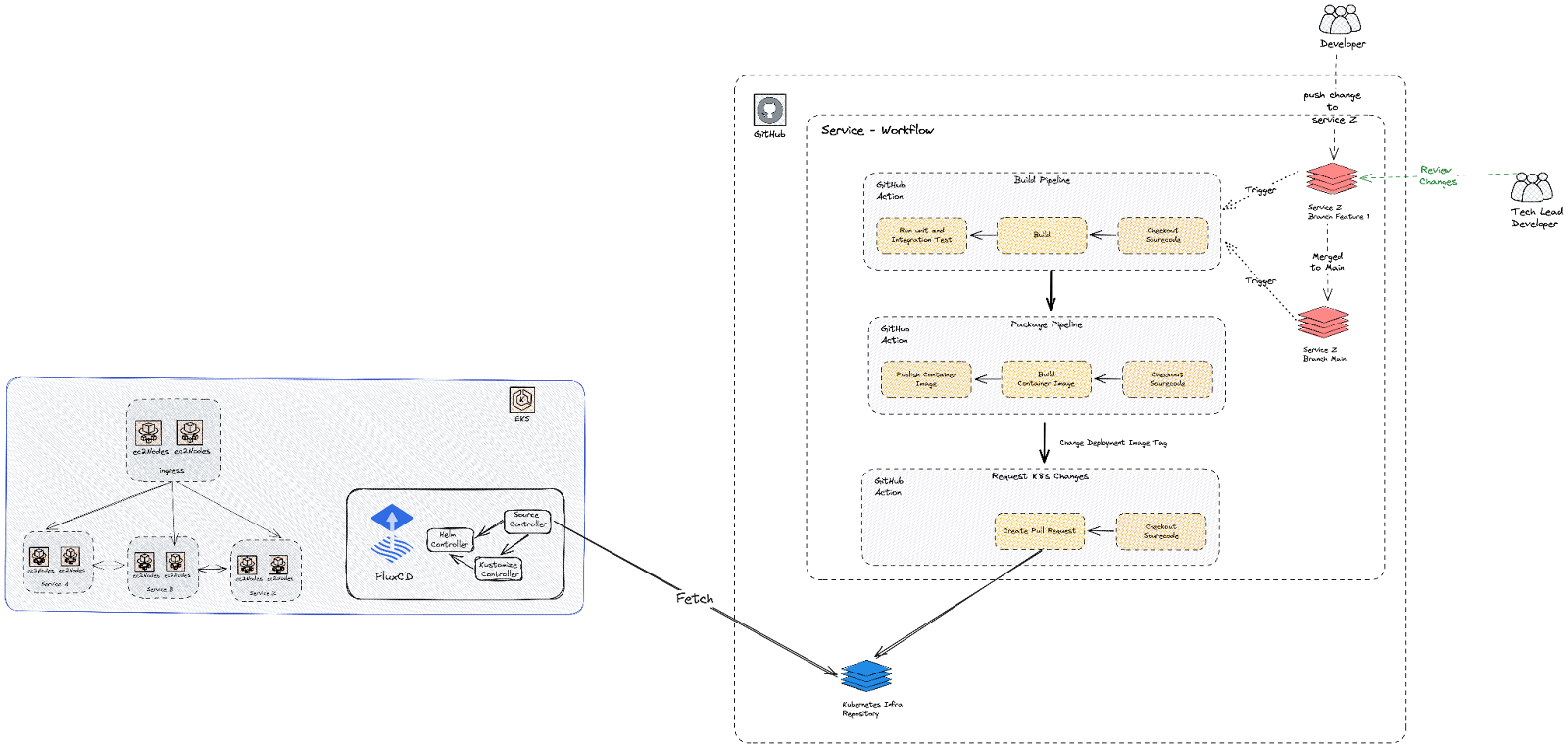
- All Kubernetes configurations were stored in Git, providing a single source of truth.
- FluxCD automatically synced configurations with the clusters, ensuring they always reflected the desired state.
- Rollbacks were straightforward, thanks to Git’s versioning and traceability.
Managing Secrets in Kubernetes
One of the most sensitive aspects of managing Kubernetes is handling secrets—credentials, API keys, and other sensitive data that applications need. For us, managing secrets was about striking a balance between security and usability.
We adopted a hybrid approach for secret management:
- AWS Secrets Manager: Used for most application secrets, providing centralized management and integration with other AWS services.
- SOPS (Secrets Operations): Used for encrypting secrets directly in Git repositories for specific application use cases. SOPS allowed us to store secrets securely in Git while maintaining compatibility with GitOps workflows.
To ensure that secrets were securely injected into Kubernetes:
- Secrets were retrieved or decrypted during deployment and stored as Kubernetes secrets.
- Pods accessed these secrets through environment variables, ensuring that sensitive data never resided directly in the application codebase or the Git repository in plain text.
This approach allowed us to leverage the scalability and convenience of AWS Secrets Manager while keeping GitOps workflows clean and manageable with SOPS for application-specific needs.
Measuring Success with DevOps Metrics
To evaluate the success of our DevOps implementation, we tracked several key metrics that reflected our expectations:
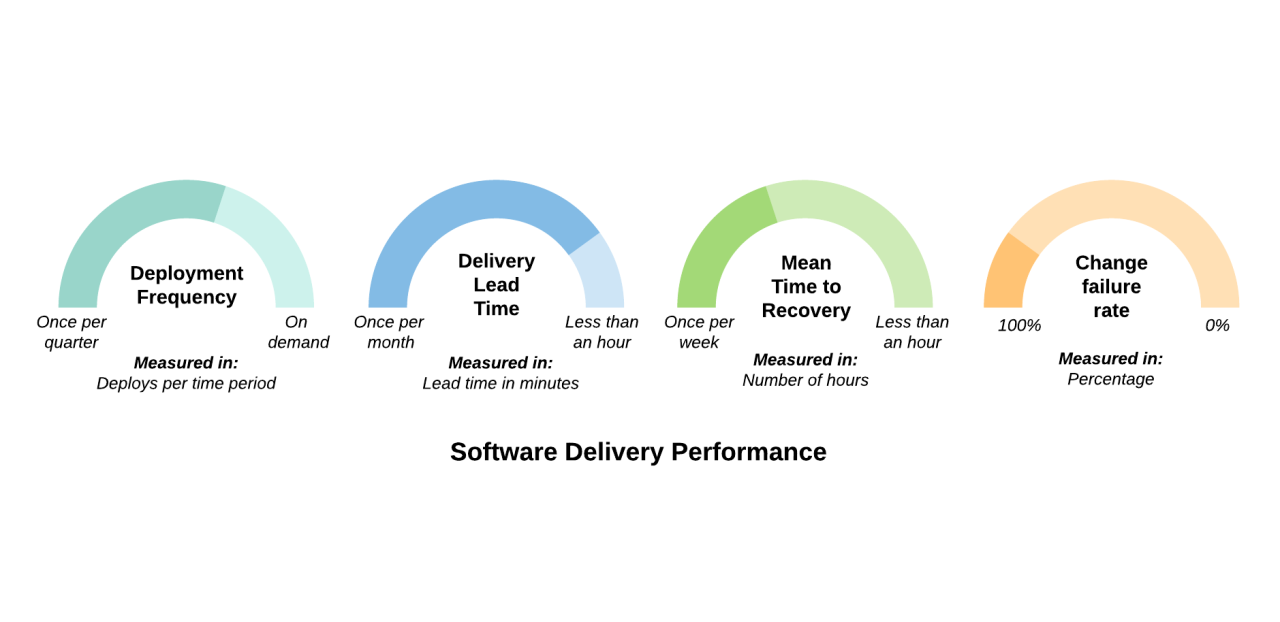
Ref: https://www.linkedin.com/pulse/four-key-metrics-devops-success-craig-edwards/
- Deployment Frequency How often can we deploy changes to production?
- High deployment frequency indicates a well-automated pipeline and confidence in the process.
- Our goal was to deploy updates regularly and safely, enabling continuous improvements to our infrastructure and user experience.
- Lead Time for Changes How quickly can we move from committing code to deploying it?
- A shorter lead time signals an efficient pipeline with minimal friction.
- We aimed to reduce delays, ensuring that bug fixes and features reached production as fast as possible.
- Change Failure Rate What percentage of changes result in failures or rollbacks?
- A low failure rate reflects strong testing and reliable automation.
- By integrating automated tests and CI/CD pipelines, we reduced deployment failures significantly.
- Mean Time to Recovery (MTTR) How quickly can we recover from an incident?
- A low MTTR indicates robust monitoring, alerting, and rollback mechanisms.
- By using GitOps and IaC, we could diagnose and fix issues swiftly, restoring systems to their desired state.
Tracking these metrics provided tangible feedback on how well our DevOps practices aligned with our goals. Improvements in these areas directly contributed to Electrum’s ability to scale operations and maintain reliability.
DevOps in Action: A Foundation for Growth By designing a DevOps framework tailored to our needs, we built a system that was consistent, scalable, and adaptable. Automation became the cornerstone of our approach, enabling us to implement practices like IaC, CI/CD, and GitOps with confidence.
Infrastructure in Kubernetes: Nodes and Beyond
By the time our Kubernetes clusters were up and running, we faced a new challenge: how to manage the infrastructure efficiently. Kubernetes nodes—the servers running our workloads—were at the core of this challenge. As a young company, we couldn’t afford to let costs spiral out of control or deal with underutilized resources. At the same time, we needed to ensure our systems were reliable and ready to scale.
Managing nodes in Kubernetes isn’t just about picking the right instance types. It’s like solving a moving puzzle, where every workload has different needs, and the pieces have to fit together to avoid waste. Getting it right required thoughtful planning, some trial and error, and a willingness to adapt as we learned what worked.
AWS Pricing Models: Balancing Cost and Flexibility

The first step in optimizing our Kubernetes infrastructure was understanding AWS pricing models. Each model offered unique benefits for different workloads:
- On-Demand Instances with Savings Plans
On-demand instances are billed per second and provide the flexibility to scale workloads as needed, without long-term commitments. To manage costs for predictable workloads, we paired on-demand instances with AWS Savings Plans. These plans allowed us to commit to a certain level of usage over one or three years, offering significant cost savings while retaining flexibility. This combination was ideal for critical, stateful services like databases, where reliability and consistent availability were non-negotiable. - Spot Instances
Spot instances offer discounts of up to 70% compared to on-demand pricing but come with the trade-off that AWS can reclaim them at any time. This made them suitable for fault-tolerant workloads, such as services with failover mechanisms or distributed processing jobs. To deploy these services on spot instances, we implemented:- A good shutdown mechanism to handle interruptions gracefully.
- Service discovery to reroute traffic during node failures.
- Multiple replicas with pod affinity rules to ensure they weren’t deployed to a single node, increasing redundancy and resilience.
- Graviton Instances
AWS’s ARM-based Graviton instances offered significant cost savings of up to 30% compared to Intel-based instances. Wherever possible, we prioritized workloads compatible with ARM architecture to take advantage of these savings without compromising performance.
This hybrid approach allowed us to optimize costs while maintaining the reliability and scalability required to support Electrum’s operations.
Enter Karpenter: Simplifying Node Management
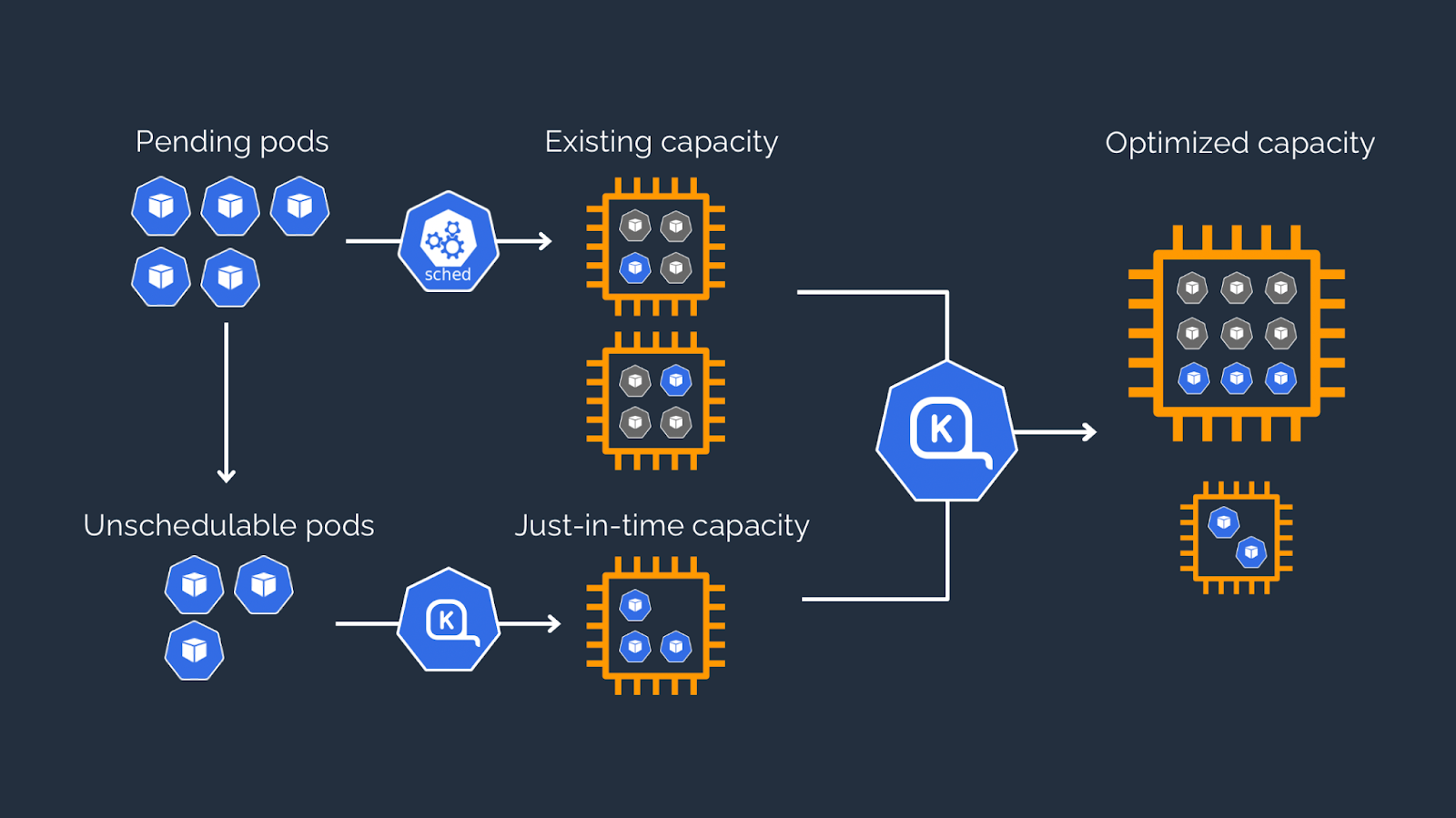
Ref: https://karpenter.sh/karpenter-overview.png
{kind=link}
Even with a clear cost strategy, managing nodes at scale became increasingly complex. Ensuring optimal utilization and avoiding fragmentation felt like solving a Tetris puzzle that never stopped. That’s when we turned to Karpenter, an open-source Kubernetes cluster autoscaler designed for flexibility and simplicity.
Karpenter revolutionized how we managed nodes:
- Dynamic scaling: Nodes were provisioned in real-time based on workload demands, eliminating the need for manual intervention.
- Spot instance optimization: When AWS reclaimed a spot instance, Karpenter automatically replaced it and migrated pods seamlessly.
- Instance type selection: Karpenter dynamically chose the best instance type for each workload, further optimizing costs.
This was a game-changer. Instead of worrying about managing node groups manually, Karpenter allowed us to focus on optimizing workloads and scaling the business.
Real-World Challenges: Lessons Learned
While Karpenter and AWS’s pricing models made optimization easier, there were still lessons learned along the way:
- Balancing cost and reliability: Finding the right mix of spot and on-demand instances required experimentation. Early on, we relied too heavily on spot instances for some production workloads, leading to unnecessary churn. Adjusting the mix improved stability.
- Managing diverse workloads: Some workloads had unique requirements (e.g., high memory, specialized hardware), which required extra tuning and testing.
- Observability and automation: Scaling nodes dynamically was only as effective as our monitoring and alerting. We invested heavily in observability tools to ensure we could spot inefficiencies or issues early.
Nodes in Kubernetes: Beyond Cost Optimization Optimizing nodes wasn’t just about cutting costs—it was about aligning with Electrum’s mission of sustainability. By efficiently managing resources, we reduced energy waste and minimized the carbon footprint of our infrastructure.
Strategic Approach to Managed vs. Self-Managed Services
As we scaled Electrum’s infrastructure, we faced a fundamental question: should we rely on managed services provided by cloud vendors or build and manage these services ourselves? The answer wasn’t straightforward. It required balancing cost efficiency, operational overhead, and flexibility to meet both immediate and long-term goals.
Managed vs. Self-Managed: The Trade-offs

Managed services like RDS for databases or Amazon MSK for Kafka simplify operations by offloading maintenance tasks, such as backups and upgrades. However, they often come with higher costs and limited flexibility. On the other hand, self-managed solutions provide greater control and cost savings but require more effort to set up and maintain.
For us, the decision came down to this question: Would the benefits of using a managed service outweigh the additional cost and potential vendor lock-in? In most cases, the answer was no. Instead, we leaned toward self-managing services whenever it made sense, using automation and DevOps practices to minimize operational overhead.
Criteria for Choosing Self-Managed vs. Managed Services
To make these decisions, we established a simple set of criteria:
- Operational Complexity
Could we self-manage the service without introducing excessive complexity? For example, services with robust Kubernetes operators were often easier to manage than those requiring custom scripts or manual interventions. - Cost vs. Value
Did the managed service justify its higher cost compared to a self-managed alternative? If we could achieve similar reliability and performance by managing the service ourselves, we prioritized cost efficiency. - Flexibility
Managed services often have limitations in customization or configuration. If these limitations conflicted with our needs, we opted for self-management.
Balancing Operational Overhead
Self-managing services isn’t without its challenges. It requires careful planning, automation, and a commitment to ongoing maintenance. To reduce operational overhead, we adopted several strategies:
- Automation First: Wherever possible, we used Kubernetes operators or Helm charts to handle day-2 operations like backups and scaling.
- Containerization: Deploying services as containers ensured consistency and simplified deployments across environments.
- Monitoring and Alerts: Proactive monitoring with observability tools helped us identify and address issues early, minimizing downtime.
Here are some of the key services we chose to self-manage:
1. Databases
For PostgreSQL, we explored Kubernetes operators like Crunchy Data, Zalando, and CloudNativePG. After testing, we selected CloudNativePG for its simplicity, active community support, and Kubernetes-native design. It automated tasks like backups, failovers, and scaling, making self-management a practical choice.
2. Kafka
Instead of Amazon MSK, we opted to self-manage Kafka using the Strimzi operator. Strimzi provided tight integration with Kubernetes, automating broker scaling, topic management, and failover. This approach gave us full control over Kafka configurations while avoiding the cost premium of MSK.
3. Observability Tools
We built our own observability stack with VictoriaMetrics, VictoriaLogs, and Grafana instead of using managed services like Amazon Managed Prometheus and Grafana. This allowed us to scale monitoring and logging cost-effectively while retaining full control over configurations.
4. Redis
For caching, we deployed Redis with Helm charts and configured it with replicas and Sentinel for high availability. This setup ensured that clients could failover to healthy replicas in case of a node failure.
5. Analytics System
For analytics, we built a stack using ClickHouse for data storage and Metabase for visualization. ClickHouse was deployed using the Altinity operator, which automated tasks like scaling, backups, and updates. This setup provided us with powerful analytics capabilities while avoiding the high costs of managed analytics solutions.
When We Chose Managed Services
While self-management was our default approach, there were exceptions. For instance:
- AWS Secrets Manager: We used it for managing sensitive secrets across our infrastructure. Its integration with other AWS services simplified secret rotation and access management.
- Amazon S3: For object storage, we chose S3 for its reliability and scalability, as building our own or self hosted Minio would have added unnecessary complexity.
Lessons Learned: The Long-Term View
Choosing between managed and self-managed services isn’t a one-size-fits-all decision. For us, leaning toward self-management allowed us to optimize costs and maintain control over critical systems. However, it also meant investing in automation and operational practices to keep maintenance manageable.
The key takeaway? It’s not just about saving money—it’s about creating a sustainable and adaptable infrastructure that aligns with your team’s capabilities and long-term goals.
Electrum’s Achievements: Technology in Action
By leveraging strategy, automation, containerization, and GitOps, we've built a cost-effective infrastructure that powers our mission to revolutionize urban mobility.
Despite being a lean team of just 4-5 software engineers, we have successfully developed Electrum's technology platform from scratch, which consists of:
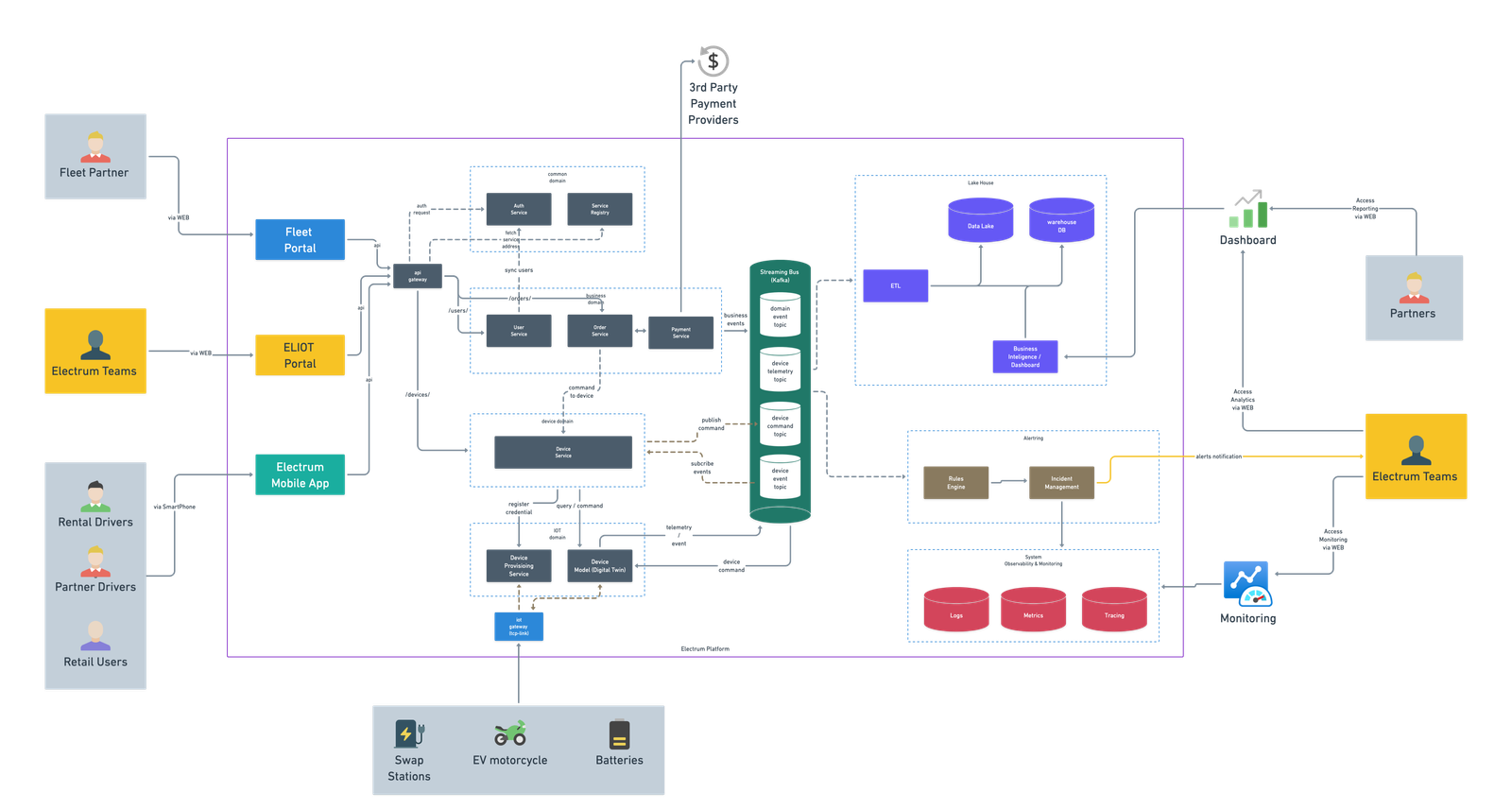
- IoT Platform: Managing real-time data for fleet and battery operations.
- Transaction Engine: Enabling smooth financial and operational processes.
- Fleet Management: Optimizing vehicle usage and maintenance.
- Rental Operations: Streamlining onboarding, booking, and customer management.
- Analytics Platform: Delivering insights for strategic decision-making.
Our software lifecycle efficiency enables us to introduce new services with remarkable ease—often by simply adding a folder and a few Helm and customization files. This streamlined approach allows us to scale rapidly while maintaining operational flexibility and cost efficiency.
Our accomplishments in 2024 reflect the impact of our work:
- 4,000+ Drivers adopting our sustainable mobility solutions.
- 250+ Battery Swap Stations strategically placed across Jakarta.
- 8.8 Million Trips Completed, reinforcing platform reliability.
- 46 Million Kilometers Traveled, reducing emissions and traffic congestion.
These numbers represent more than just metrics—they’re a testament to how the right technology stack and strategic decisions can drive innovation, scalability, and sustainability.
Our Technology Stack: The Foundation of Success
Electrum’s success is built on a robust technology stack designed for scalability, efficiency, and adaptability. Here’s a summary of the key tools and strategies that powered our journey:
- Cloud Strategy: A hybrid approach leveraging AWS, combining on-demand, reserved, and spot instances, with a Graviton-first policy to optimize costs.
- DevOps Practices: Automation as the backbone, with Terraform and Terragrunt for IaC, GitHub Actions for CI/CD, and FluxCD for GitOps.
- Kubernetes Infrastructure: Dynamically managed with Karpenter, ensuring cost-efficient and resilient node scaling.
- Self-Managed Services:
- PostgreSQL with CloudNativePG for reliable databases.
- Kafka with Strimzi for scalable event streaming.
- Observability Stack with VictoriaMetrics, VictoriaLogs, and Grafana.
- Redis deployed with Helm for high-availability caching.
- Analytics Stack with ClickHouse and Metabase for real-time insights.
Each component was carefully chosen to align with our goals of cost-efficiency, operational control, and sustainability.
Key Takeaways
Building Electrum’s infrastructure from scratch taught us valuable lessons about balancing strategy, tools, and execution. Here are some high-level insights:
- Start with a Clear Strategy: Decisions like choosing the right cloud strategy or balancing managed vs. self-managed services are foundational. They set the tone for scalability and adaptability.
- Prioritize Automation: Automating everything—from infrastructure provisioning to deployments—reduces human error and frees up time for innovation.
- Measure What Matters: Tracking metrics like deployment frequency and MTTR helped us evaluate and refine our processes continuously.
- Embrace Kubernetes Wisely: Kubernetes is powerful, but managing it at scale requires thoughtful tools like Karpenter and GitOps principles for simplicity and efficiency.
- Iterate and Adapt: The needs of your infrastructure will evolve. Regularly revisit your architecture to ensure it remains aligned with your goals.
A Vision for the Future
At Electrum, every decision we make is driven by our mission to transform urban mobility and contribute to a more sustainable future. The journey doesn’t end here. As we continue to scale, we’re focused on leveraging technology to deliver an even better rider experience, optimize operations, and expand our impact.
We hope our journey provides valuable insights for others building scalable systems. What challenges or successes have you encountered in scaling your infrastructure? Let’s keep the conversation going—share your thoughts in the comments below!
Reference
- Terraform: An open-source tool for building, changing, and versioning infrastructure safely and efficiently. Terraform by HashiCorp
- Terragrunt: A thin wrapper for Terraform that provides extra tools for keeping configurations DRY and managing remote state. Terragrunt | OpenTofu/Terraform wrapper
- FluxCD: A set of continuous and progressive delivery solutions for Kubernetes, open and extensible. Flux - the GitOps family of projects
- GitHub Actions: Automate, customize, and execute your software development workflows right in your repository with GitHub Actions. GitHub
- Karpenter: An open-source Kubernetes cluster autoscaler built with flexibility, performance, and simplicity in mind. Karpenter
- CloudNativePG: A Kubernetes operator for PostgreSQL, providing high availability and disaster recovery capabilities.CloudNativePG
- Strimzi: An open-source project that provides a way to run Apache Kafka on Kubernetes in various deployment configurations.Strimzi
- VictoriaMetrics: A fast, cost-effective, and scalable monitoring solution and time series database.VictoriaMetrics
- VictoriaLogs: A log management solution that is fast, efficient, and scalable, designed to handle large volumes of log data.
- Grafana: An open-source platform for monitoring and observability, allowing you to query, visualize, alert on, and understand your metrics.Grafana
- Redis Helm Chart: A Helm chart for deploying Redis, an open-source, in-memory data structure store, used as a database, cache, and message broker.
- Metabase: An open-source business intelligence tool that lets you ask questions about your data and displays answers in formats that make sense, whether that’s a bar chart or a detailed table.Metabase
- ClickHouse: An open-source columnar database management system for online analytical processing (OLAP).ClickHouse
- Altinity Operator: A Kubernetes operator for ClickHouse, automating tasks like deployment, scaling, and management.